
Genome sequencing in crop plants
Theory
What is genome sequencing?
Genome sequencing refers to sequencing the entire genome of an organism. It is the procedure of ascertaining the entire DNA sequence of an organism's genome at a specific moment. This involves determining the exact sequence of nucleotides (adenine [A], cytosine [C], guanine [G], and thymine [T]) in the DNA molecules that make up the genome. It involves sequencing the entire genetic material of an organism, whether it is a bacterium, plant, animal or human. The foundation of all biological existence is the genetic code. Consequently, access to the core DNA sequence, namely the genome, and the encoding of genes within it, has become an essential resource in biology. In some cases, only specific regions of the genome (such as exomes, which contain protein-coding genes) are sequenced. The first plant genome that was sequenced was of Arabidopsis thaliana, was completed and published in Nature on December 14, 2000.
Whole-genome sequencing (WGS) is a comprehensive method for analyzing entire genomes. Genomic information has been instrumental in identifying inherited disorders, characterizing the mutations that drive cancer progression, and tracking disease outbreaks. Rapidly dropping sequencing costs and the ability to produce large volumes of data with today’s sequencers make whole-genome sequencing a powerful tool for genomics research [1].
Types of genome sequencing
There are multiple methods of genome sequencing. One of the oldest yet most important type of genome or gene sequencing is Sanger sequencing, developed by Sanger and Coulson in 1975, which became the gold standard for over a decade. Sanger won the Nobel Prize for his pioneering DNA sequencing method in 1980. Nowadays, we have highly efficient next-generation sequencing (NGS) technologies. This enables faster and more cost-effective sequencing, revolutionizing genomics research and applications.
a. Sanger Sequencing:
This method of sequencing was discovered by Sanger and Coulson in 1975. It is a chain termination DNA sequencing technology that utilities dideoxy nucleotides. In Sanger dideoxy DNA sequencing, a DNA- dependent polymerase is used to generate a complimentary copy of a single-stranded DNA template. technology utilizes the fact that DNA polymerases will incorporate a chain-terminating 2′,3′- dideoxynucleotide monophosphate (ddNMP) at the appropriate complementary position but synthesis will be stopped by the incorporation of the ddNMPs at the 3′ end because the next nucleotide to be added lacks the required 3′ hydroxyl group for dNMP phosphodiester bond formation. Four reactions, containing template, polymerase, all four dNTPs, and primer, are set up to generate a continuing series of synthesis products that reflects each potential chain termination position. In addition, each reaction also contains one of the four radioactively/fluorescently labeled ddNTPs at a specific ratio reflecting the relative probability of incorporation. Many terminated strands of different lengths exist within each of the four reactions. As each reaction contains only one ddNTP species, a set of different-length fragments is generated in each reaction, terminated at all of the positions corresponding to one of the four nucleotides in the template sequence. The four reactions are then individually separated on a large denaturing polyacrylamide gel to yield single nucleotide resolution. The pattern of bands across the four lanes allows direct readout of the primary sequence of the template under analysis.
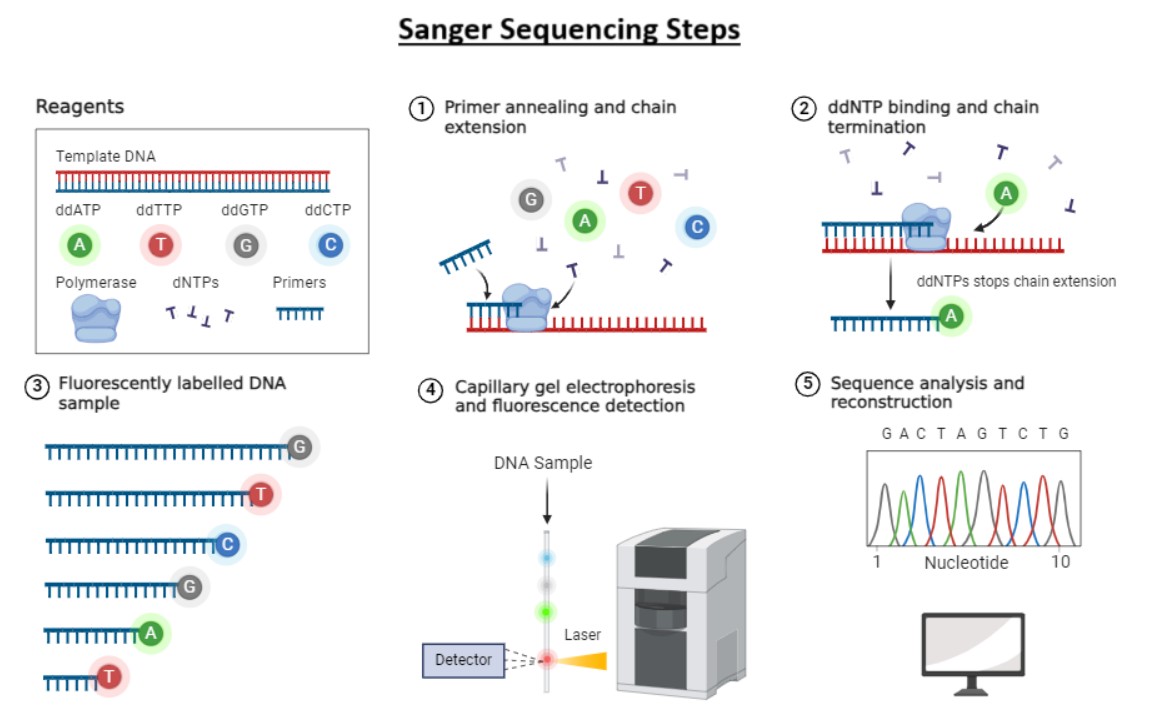
Fig 1: Steps in Sanger Sequencing (Source: [https://www.biotechreality.com/2024/10/sanger-sequencing-steps-and-process.html](https://www.biotechreality.com/2024/10/sanger-sequencing-steps-and-process.html)). Used for academic purpose.
b. Illumina Next Generation Sequencing
Illumina sequencing, one of the most popular technique of next-generation sequencing (NGS), uses sequencing-by-synthesis (SBS) chemistry to identify DNA bases. It is a high-throughput method that sequences multiple DNA fragments in parallel [2, 3, 4]. It enables rapid, accurate, and cost-effective sequencing of DNA and RNA for applications in genomics, transcriptomics, and epigenomics. In this method DNA polymerase incorporates fluorescently labeled nucleotides one at a time. The fluorescence signal is recorded at each cycle, enabling base-by-base sequencing of DNA fragments.
Advantages of Illumina Sequencing
High Accuracy – Low error rates (~ 0.1%) due to SBS chemistry. High Throughput – Generates millions to billions of reads in a single run. Cost-Effective – Competitive cost per base compared to other platforms. Versatile Applications – Whole genome sequencing (WGS), exome sequencing, RNA-seq, methylation studies, etc.
Limitations
Short Read Lengths – Typically up to 300 bp (paired-end), limiting assembly of highly repetitive regions. Relatively Long Turnaround Time – Compared to real-time sequencing methods (e.g., Oxford Nanopore).
c. Third-Generation Sequencing Long-read sequencing technologies such as PacBio (Pacific Biosciences) and Oxford Nanopore.
PacBio Sequencing: PacBio sequencing, also known as Single Molecule Real-Time (SMRT) sequencing, is a third-generation sequencing technology that uses Zero-Mode Waveguide (ZMW) technology to generate long, highly accurate reads for DNA sequencing, enabling comprehensive analysis of genomes, transcriptomes, and epigenomes [5, 6, 7,].
Principle of PacBio Sequencing
SMRT Sequencing Technology: PacBio sequencing utilizes SMRT technology, which involves confining individual DNA molecules and DNA polymerase within a ZMW pore, enabling sequencing while synthesizing, and differentiating fluorescence signals from background noise. [6, 7]
Long Reads: PacBio sequencing is known for generating long reads, which can span thousands of base pairs, making it particularly useful for resolving complex regions of the genome, such as repetitive sequences and structural variations. [8, 9]
HiFi Sequencing: PacBio has developed HiFi sequencing, which provides highly accurate long reads, with accuracy approaching that of short-read sequencing technologies like Illumina. [10, 11]
Advantages of PacBio Sequencing:
- Long Reads (HiFi Reads up to 100 kb) → Suitable for resolving structural variants, genome assembly, and full-length transcript sequencing.
- High Accuracy (HiFi mode with >99.9% accuracy) → Achieved by circular consensus sequencing (CCS).
- Real-Time Sequencing → No need for PCR amplification, reducing bias and artifacts.
- Epigenetic Detection → Can detect DNA modifications like methylation without additional processing.
d. Nanopore Sequencing:
Nanopore sequencing is the fourth generation of DNA sequencing technology, with notable advantages of nanopores (either biological or solid-state) include label-free operation, ultralong reads (ranging from 104 to 106 bases), high throughput, and minimal material requirements. Each of them significantly streamlines the experimental procedure and is readily applicable for DNA sequencing purposes. Nanopore sequencing technology, created by Oxford Nanopore Technologies Ltd., represents the most effective way for the fast creation of long-read sequences. Nanopore sequencing enables the sequencing of a single DNA or RNA molecule without requiring PCR amplification or chemical labeling of the sample.
Nanopore sequencing possesses the capability to provide cost-effective genotyping, enhanced portability for testing, and swift sample processing, along with the capacity to present results in real time. Nanopore sequencing employs electrophoresis to convey an unidentified sample through an aperture measuring 10−9 m in diameter. A nanopore system invariably includes an electrolytic solution, and when a continuous electric field is provided, an electric current is detectable within the system. The intensity of the electric current density across a nanopore surface is contingent upon the nanopore's dimensions and the composition of the DNA or RNA inside it. Sequencing is facilitated by the fact that samples induce distinctive alterations in electric current density on nanopore surfaces when in proximity to them. Nanopore sequencing relies on passing single strands of DNA or RNA molecules through a tiny protein channel (nanopore) embedded in an electrically resistant membrane. As the DNA molecule passes through the nanopore, it causes changes in the ion current, which can be used to determine the sequence as well as modifications of bases [12].
Working:
- Nanopores are tiny holes, typically made of protein or synthetic materials, embedded in a membrane. [13, 14]
- Single-stranded DNA or RNA molecules are passed through these pores.
- As different nucleotides pass through the pore, they alter the electrical current flowing through it.
- These current changes are detected and converted into a sequence of bases (A, T, C, G). [14]
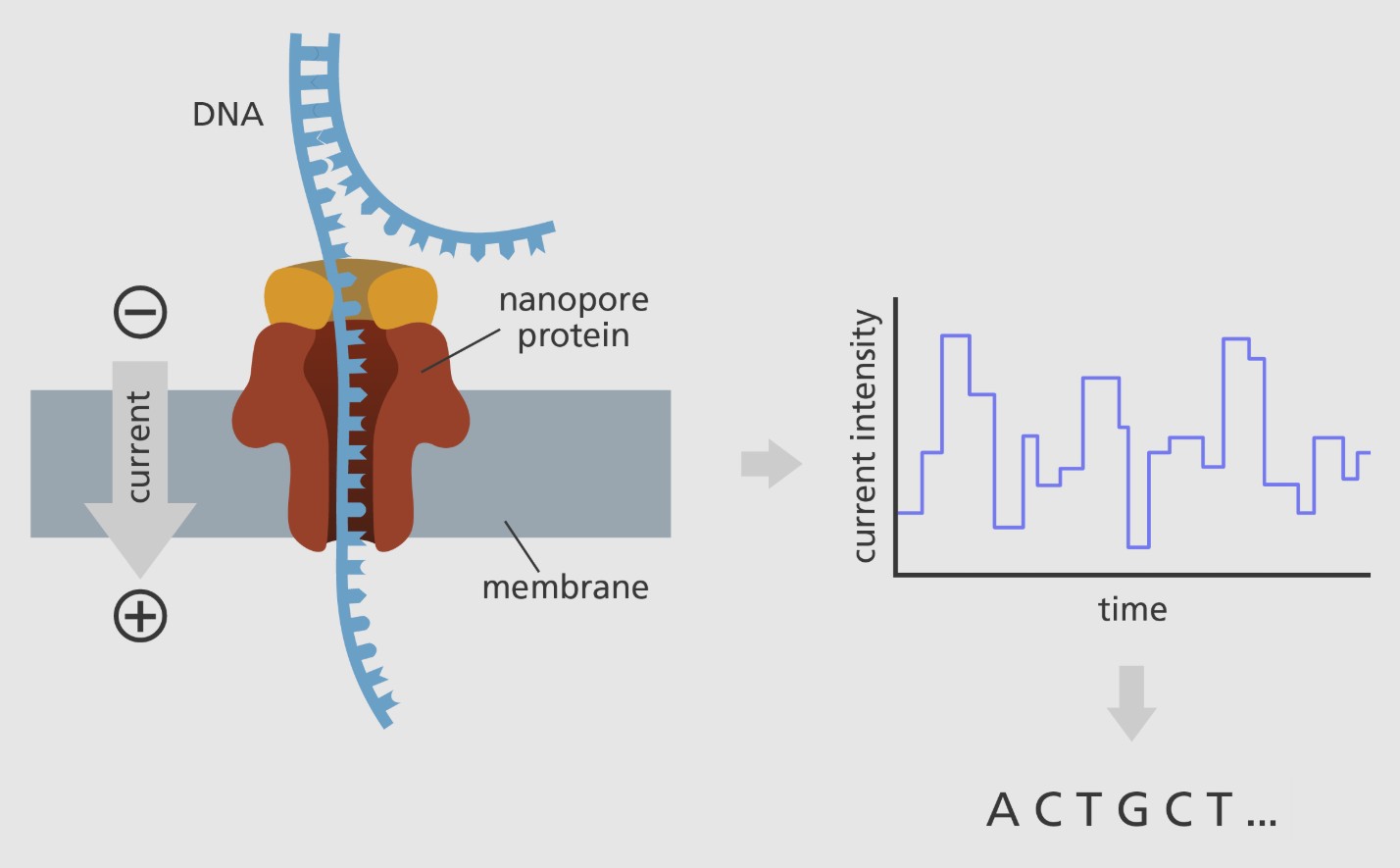
Fig 2: Nanopore Sequencing (Source: [https://www.yourgenome.org/theme/what-is-oxford-nanopore-technology-ont-sequencing/](https://www.yourgenome.org/theme/what-is-oxford-nanopore-technology-ont-sequencing/)). Used for academic purpose
Advantages of Nanopore Sequencing:
- Ultra-long read lengths: Nanopore sequencing can produce reads that are much longer than those from other sequencing technologies, allowing for the analysis of larger genomic regions. [17, 18]
- Real-time sequencing: The process is real-time, meaning that the sequencing data is generated as the DNA passes through the pore. [15]
- Direct sequencing: Nanopore sequencing directly sequences DNA or RNA without the need for PCR amplification or chemical labeling. [15]
- Scalability: The technology is available in various formats, from portable devices to high-throughput systems. [15, 16]
Applications of genome sequencing in crop plants
a. Genome mapping and functional genomics:
Whole genome sequencing (WGS) is transforming genome mapping and functional genomics by allowing thorough investigation of an organism's complete DNA sequence, hence aiding the identification of genetic variants, pathogenic mutations, and innovative genome assemblies for diverse applications [16, 17, 18]. WGS offers a complete comprehensive overview of the genome, in contrast to targetted methods such as exome sequencing, facilitating the detection of a wider array of genetic variations, including single nucleotide variants, insertions/deletions, copy number alterations, and extensive structural variants [17, 18]. WGS also helps to identify genes and regulatory elements involved in various important metabolic pathways in plants and other organisms. WGS enables the analysis of genetic variations, including single nucleotide polymorphisms (SNPs), insertions/deletions, and copy number variations, to understand their functional consequences [19].
b. Marker-Assisted Selection (MAS) and breeding:
Whole genome sequencing (WGS) enhances Marker-Assisted Selection (MAS) and breeding by providing high-throughput data for identifying and genotyping SNPs, enabling precise selection of desirable traits and accelerating crop improvement. MAS is a breeding technique that uses molecular markers (like SNPs) to select for desirable traits in plants or animals. Instead of relying solely on phenotypic observations, MAS allows breeders to identify individuals carrying specific genes or genomic regions associated with desired traits, even if those traits are not yet expressed. This approach can accelerate breeding programs, reduce selection time, and improve the accuracy of selection [20, 21, 22].
c. Crop improvement through genetic engineering and CRISPR editing:
Whole genome sequencing (WGS) gives us the sequence information and location of each and every gene present in the genome. Through genetic engineering, we can clone and overexpress the beneficial genes that are responsible for a desirable phenotype. Via CRISPR-Cas9 genome editing technology, it is possible to knockout the genes that may produce metabolites in crops that are unsuitable for consumption. By genetic engineering processes and CRISPR editing methods, we can increase the nutritional quality of crops. One of the major examples of this is golden rice, the generic name given to genetically modified rice that produces β-carotene (provitamin A) in the endosperm. Genes coding for the important enzymes of the carotenoid biosynthetic pathway like phytoene synthase (PSY), phytoene desaturase (PDS), carotenoid isomerase (CrtISO), and lycopene β-cyclase (β-LCY) were cloned and transformed into japonica rice via Agrobacterium-mediated transformation. This was done to tackle the Vitamin A deficiency in humans, which causes multiple eye and vision related disorders like night blindness, drying of the conjunctiva and cornea, etc. Prolonged deficiency led to irreversible blindness [23].
d. Disease and pest resistance:
WGS provides us the sequence information of genes, whose phenotype leads to disease and pest resistance in crop plants. Overexpression or heterologous expression of those genes in crop plants can enhance their disease and pest resistance capabilities. One of the major examples is Bt cotton which had been genetically altered through the incorporation of one or more genes from the ubiquitous soil bacteria, Bacillus thuringiensis. These genes facilitate the synthesis of insecticidal proteins, enabling genetically modified plants to generate one or more poisons during their growth. The genes introduced into cotton generate poisons that mostly affect caterpillar pests (Lepidoptera). Nonetheless, alternative strains of Bacillus thuringiensis possess genes that encode toxins exhibiting insecticidal properties against some beetles (Coleoptera) and flies (Diptera) [24].
e. Climate-resilient crops and abiotic stress tolerance:
Abiotic stressors include salinity, drought, severe temperatures, and oxidative stress reduce crop production by over 50%. Due to global warming, these abiotic pressures may grow soon. Abiotic stressors cause dehydration or osmotic stress by reducing water availability for cellular processes and turgor pressure and increasing ROS production. To deal with stress, plants have evolved cellular and metabolic modifications. Recent advances in molecular genetics have helped us understand the biochemical and genetic underpinnings of abiotic stress tolerance. Abiotic stress-tolerant plants with higher yields have been developed by modulating the expression of genes that encode enzymes involved in the biosynthesis of osmoprotectants (proline, sugars, sugar alcohol, glycine betaine, and polyamines), antioxidant enzymes, protective proteins (LEAs and HSPs), transporters, regulatory proteins, kinases, and transcription factors. Now, posttranscriptional and posttranslational regulation mechanisms of the abiotic stress response, such as microRNAs and ubiquitination, are promising modulation targets to develop abiotic stress-tolerant plants and more productive crops to feed the growing population.
Challenges in crop genome sequencing
- Large and Complex Genomes
- Polyploidy in Many Crops
- High Cost of Long-Read Sequencing
- Data Management and Analysis
Future Prospects of Genome Sequencing in Agriculture
- Pan-Genomics and Crop Diversity Studies
- Integration with AI and Machine Learning
- More Affordable and Faster Sequencing
- Synthetic Biology and Designer Crops
- Personalized Agriculture and Smart Farming